Технология cuda что. Компьютерный ресурс У SM
И предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением.cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования, например в NetBeans .
В архитектуре CUDA используется модель памяти грид , кластерное моделирование потоков и SIMD -инструкции. Применима не только для высокопроизводительных графических вычислений, но и для различных научных вычислений с использованием видеокарт nVidia. Ученые и исследователи широко используют CUDA в различных областях, включая астрофизику , вычислительную биологию и химию, моделирование динамики жидкостей, электромагнитных взаимодействий, компьютерную томографию, сейсмический анализ и многое другое. В CUDA имеется возможность подключения к приложениям, использующим OpenGL и Direct3D . CUDA - кроссплатформенное программное обеспечение для таких операционных систем как Linux , Mac OS X и Windows .
22 марта 2010 года nVidia выпустила CUDA Toolkit 3.0, который содержал поддержку OpenCL .
Оборудование
Платформа CUDA Впервые появились на рынке с выходом чипа NVIDIA восьмого поколения G80 и стала присутствовать во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce , Quadro и NVidia Tesla .
Первая серия оборудования, поддерживающая CUDA SDK, G8x, имела 32-битный векторный процессор одинарной точности , использующий CUDA SDK как API (CUDA поддерживает тип double языка Си, однако сейчас его точность понижена до 32-битного с плавающей запятой). Более поздние процессоры GT200 имеют поддержку 64-битной точности (только для SFU), но производительность значительно хуже, чем для 32-битной точности (из-за того, что SFU всего два на каждый потоковый мультипроцессор, а скалярных процессоров - восемь). Графический процессор организует аппаратную многопоточность, что позволяет задействовать все ресурсы графического процессора. Таким образом, открывается перспектива переложить функции физического ускорителя на графический ускоритель (пример реализации - nVidia PhysX). Также открываются широкие возможности использования графического оборудования компьютера для выполнения сложных неграфических вычислений: например, в вычислительной биологии и в иных отраслях науки.
Преимущества
По сравнению с традиционным подходом к организации вычислений общего назначения посредством возможностей графических API, у архитектуры CUDA отмечают следующие преимущества в этой области:
Ограничения
- Все функции, выполнимые на устройстве, не поддерживают рекурсии (в версии CUDA Toolkit 3.1 поддерживает указатели и рекурсию) и имеют некоторые другие ограничения
Поддерживаемые GPU и графические ускорители
Перечень устройств от производителя оборудования Nvidia с заявленной полной поддержкой технологии CUDA приведён на официальном сайте Nvidia: CUDA-Enabled GPU Products (англ.) .
Фактически же, в настоящее время на рынке аппаратных средств для ПК поддержку технологии CUDA обеспечивают следующие периферийные устройства :
| Версия спецификации | GPU | Видеокарты |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32/370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GTX 660M, GeForce GT 650M, GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Модели Tesla C1060, Tesla S1070, Tesla C2050/C2070, Tesla M2050/M2070, Tesla S2050 позволяют производить вычисления на GPU с двойной точностью.
Особенности и спецификации различных версий
| Feature support (unlisted features are supported for all compute capabilities) |
Compute capability (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32-bit words in global memory |
Нет | Да | |||
floating point values in global memory |
|||||
| Integer atomic functions operating on 32-bit words in shared memory |
Нет | Да | |||
| atomicExch() operating on 32-bit floating point values in shared memory |
|||||
| Integer atomic functions operating on 64-bit words in global memory |
|||||
| Warp vote functions | |||||
| Double-precision floating-point operations | Нет | Да | |||
| Atomic functions operating on 64-bit integer values in shared memory |
Нет | Да | |||
| Floating-point atomic addition operating on 32-bit words in global and shared memory |
|||||
| _ballot() | |||||
| _threadfence_system() | |||||
| _syncthreads_count(), _syncthreads_and(), _syncthreads_or() |
|||||
| Surface functions | |||||
| 3D grid of thread block | |||||
| Technical specifications | Compute capability (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Maximum dimensionality of grid of thread blocks | 2 | 3 | |||
| Maximum x-, y-, or z-dimension of a grid of thread blocks | 65535 | ||||
| Maximum dimensionality of thread block | 3 | ||||
| Maximum x- or y-dimension of a block | 512 | 1024 | |||
| Maximum z-dimension of a block | 64 | ||||
| Maximum number of threads per block | 512 | 1024 | |||
| Warp size | 32 | ||||
| Maximum number of resident blocks per multiprocessor | 8 | ||||
| Maximum number of resident warps per multiprocessor | 24 | 32 | 48 | ||
| Maximum number of resident threads per multiprocessor | 768 | 1024 | 1536 | ||
| Number of 32-bit registers per multiprocessor | 8 K | 16 K | 32 K | ||
| Maximum amount of shared memory per multiprocessor | 16 KB | 48 KB | |||
| Number of shared memory banks | 16 | 32 | |||
| Amount of local memory per thread | 16 KB | 512 KB | |||
| Constant memory size | 64 KB | ||||
| Cache working set per multiprocessor for constant memory | 8 KB | ||||
| Cache working set per multiprocessor for texture memory | Device dependent, between 6 KB and 8 KB | ||||
| Maximum width for 1D texture |
8192 | 32768 | |||
| Maximum width for 1D texture reference bound to linear memory |
2 27 | ||||
| Maximum width and number of layers for a 1D layered texture reference |
8192 x 512 | 16384 x 2048 | |||
| Maximum width and height for 2D texture reference bound to linear memory or a CUDA array |
65536 x 32768 | 65536 x 65535 | |||
| Maximum width, height, and number of layers for a 2D layered texture reference |
8192 x 8192 x 512 | 16384 x 16384 x 2048 | |||
| Maximum width, height and depth for a 3D texture reference bound to linear memory or a CUDA array |
2048 x 2048 x 2048 | ||||
| Maximum number of textures that can be bound to a kernel |
128 | ||||
| Maximum width for a 1D surface reference bound to a CUDA array |
Not supported |
8192 | |||
| Maximum width and height for a 2D surface reference bound to a CUDA array |
8192 x 8192 | ||||
| Maximum number of surfaces that can be bound to a kernel |
8 | ||||
| Maximum number of instructions per kernel |
2 million | ||||
Пример
CudaArray* cu_array; texture< float , 2 > tex; // Allocate array cudaMalloc( & cu_array, cudaCreateChannelDesc< float> () , width, height ) ; // Copy image data to array cudaMemcpy( cu_array, image, width* height, cudaMemcpyHostToDevice) ; // Bind the array to the texture cudaBindTexture( tex, cu_array) ; // Run kernel dim3 blockDim(16 , 16 , 1 ) ; dim3 gridDim(width / blockDim.x , height / blockDim.y , 1 ) ; kernel<<< gridDim, blockDim, 0 >>> (d_odata, width, height) ; cudaUnbindTexture(tex) ; __global__ void kernel(float * odata, int height, int width) { unsigned int x = blockIdx.x * blockDim.x + threadIdx.x ; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y ; float c = texfetch(tex, x, y) ; odata[ y* width+ x] = c; }
Import pycuda.driver as drv import numpy drv.init () dev = drv.Device (0 ) ctx = dev.make_context () mod = drv.SourceModule (""" __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """ ) multiply_them = mod.get_function ("multiply_them" ) a = numpy.random .randn (400 ) .astype (numpy.float32 ) b = numpy.random .randn (400 ) .astype (numpy.float32 ) dest = numpy.zeros_like (a) multiply_them( drv.Out (dest) , drv.In (a) , drv.In (b) , block= (400 , 1 , 1 ) ) print dest-a*b
CUDA как предмет в вузах
По состоянию на декабрь 2009 года, программная модель CUDA преподается в 269 университетах по всему миру. В России обучающие курсы по CUDA читаются в Санкт-Петербургском политехническом университете , Ярославском государственном университете им. П. Г. Демидова , Московском , Нижегородском , Санкт-Петербургском , Тверском , Казанском , Новосибирском , Новосибирском государственном техническом университете Омском и Пермском государственных университетах, Международном университете природы общества и человека «Дубна» , Ивановском государственном энергетическом университете , Белгородский государственный университет , МГТУ им. Баумана , РХТУ им. Менделеева , Межрегиональном суперкомпьютерном центре РАН, . Кроме того, в декабре 2009 года было объявлено о начале работы первого в России научно-образовательного центра «Параллельные вычисления», расположенного в городе Дубна , в задачи которого входят обучение и консультации по решению сложных вычислительных задач на GPU.
На Украине курсы по CUDA читаются в Киевском институте системного анализа.
Ссылки
Официальные ресурсы
- CUDA Zone (рус.) - официальный сайт CUDA
- CUDA GPU Computing (англ.) - официальные веб-форумы, посвящённые вычислениям CUDA
Неофициальные ресурсы
Tom"s Hardware- Дмитрий Чеканов. nVidia CUDA: вычисления на видеокарте или смерть CPU? . Tom"s Hardware (22 июня 2008 г.). Архивировано
- Дмитрий Чеканов. nVidia CUDA: тесты приложений на GPU для массового рынка . Tom"s Hardware (19 мая 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 19 мая 2009.
- Алексей Берилло. NVIDIA CUDA - неграфические вычисления на графических процессорах. Часть 1 . iXBT.com (23 сентября 2008 г.). Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Алексей Берилло. NVIDIA CUDA - неграфические вычисления на графических процессорах. Часть 2 . iXBT.com (22 октября 2008 г.). - Примеры внедрения NVIDIA CUDA. Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Боресков Алексей Викторович. Основы CUDA (20 января 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Владимир Фролов. Введение в технологию CUDA . Сетевой журнал «Компьютерная графика и мультимедиа» (19 декабря 2008 г.). Архивировано из первоисточника 4 марта 2012. Проверено 28 октября 2009.
- Игорь Осколков. NVIDIA CUDA – доступный билет в мир больших вычислений . Компьютерра (30 апреля 2009 г.). Проверено 3 мая 2009.
- Владимир Фролов. Введение в технологию CUDA (1 августа 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 3 апреля 2010.
- GPGPU.ru . Использование видеокарт для вычислений
- . Центр Параллельных Вычислений
Примечания
См. также
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Графические процессоры |
| |||||||
Новая технология — как вновь возникший эволюционный вид. Странное создание, непохожее на многочисленных старожилов. Местами неуклюжее, местами смешное. И поначалу его новые качества кажутся ну никак не подходящими для этого обжитого и стабильного мира.
Однако проходит немного времени, и оказывается, что новичок бегает быстрее, прыгает выше и вообще сильнее. И мух он лопает больше его соседей-ретроградов. И вот тогда эти самые соседи начинают понимать, что ссориться с этим бывшим неуклюжим не стоит. Лучше с ним дружить, а еще лучше организовать симбиоз. Глядишь, и мух перепадет побольше.
Технология GPGPU (General-Purpose Graphics Processing Units — графический процессор общего назначения) долгое время существовала только в теоретических выкладках мозговитых академиков. А как иначе? Предложить кардинально изменить сложившийся за десятилетия вычислительный процесс, доверив расчет его параллельных веток видеокарте, — на это только теоретики и способны.
Логотип технологии CUDA напоминает о том, что выросла она в недрах
3D-графики.
Но долго пылиться на страницах университетских журналов технология GPGPU не собиралась. Распушив перья своих лучших качеств, она привлекла к себе внимание производителей. Так на свет появилась CUDA — реализация GPGPU на графических процессорах GeForce производства компании nVidia.
Благодаря CUDA технологии GPGPU стали мейнстримом. И ныне только самый недальновидный и покрытый толстым слоем лени разработчик систем программирования не заявляет о поддержке своим продуктом CUDA. IT-издания почли за честь изложить подробности технологии в многочисленных пухлых научно-популярных статьях, а конкуренты срочно уселись за лекала и кросскомпиляторы, чтобы разработать нечто подобное.
Публичное признание — это мечта не только начинающих старлеток, но и вновь зародившихся технологий. И CUDA повезло. Она на слуху, о ней говорят и пишут.
Вот только пишут так, словно продолжают обсуждать GPGPU в толстых научных журналах. Забрасывают читателя грудой терминов типа «grid», «SIMD», «warp», «хост», «текстурная и константная память». Погружают его по самую маковку в схемы организации графических процессоров nVidia, ведут извилистыми тропами параллельных алгоритмов и (самый сильный ход) показывают длинные листинги кода на языке Си. В результате получается, что на входе статьи мы имеем свежего и горящего желанием понять CUDA читателя, а на выходе — того же читателя, но с распухшей головой, заполненной кашей из фактов, схем, кода, алгоритмов и терминов.
А между тем цель любой технологии — сделать нашу жизнь проще. И CUDA прекрасно с этим справляется. Результаты ее работы — именно это убедит любого скептика лучше сотни схем и алгоритмов.
Далеко не везде
CUDA поддерживается высокопроизводительными суперкомпьютерами
nVidia Tesla.
И все же прежде, чем взглянуть на результаты трудов CUDA на поприще облегчения жизни рядового пользователя, стоит уяснить все ее ограничения. Точно как с джинном: любое желание, но одно. У CUDA тоже есть свои ахиллесовы пятки. Одна из них — ограничения платформ, на которых она может трудиться.
Перечень видеокарт производства nVidia, поддерживающих CUDA, представлен в специальном списке, именуемом CUDA Enabled Products. Список весьма внушительный, но легко классифицируемый. В поддержке CUDA не отказывают:
Модели nVidia GeForce 8-й, 9-й, 100-й, 200-й и 400-й серий с минимумом 256 мегабайт видеопамяти на борту. Поддержка распространяется как на карты для настольных систем, так и на мобильные решения.
Подавляющее большинство настольных и мобильных видеокарт nVidia Quadro.
Все решения нетбучного ряда nvidia ION.
Высокопроизводительные HPC (High Performance Computing) и суперкомпьютерные решения nVidia Tesla, используемые как для персональных вычислений, так и для организации масштабируемых кластерных систем.
Поэтому, прежде чем применять программные продукты на базе CUDA, стоит свериться с этим списком избранных.
Кроме самой видеокарты, для поддержки CUDA требуется соответствующий драйвер. Именно он является связующим звеном между центральным и графическим процессором, выполняя роль своеобразного программного интерфейса для доступа кода и данных программы к многоядерной сокровищнице GPU. Чтобы наверняка не ошибиться, nVidia рекомендует посетить страничку драйверов и получить наиболее свежую версию.
...но сам процесс
Как работает CUDA? Как объяснить сложный процесс параллельных вычислений на особой аппаратной архитектуре GPU так, чтобы не погрузить читателя в пучину специфических терминов?
Можно попытаться это сделать, представив, как центральный процессор выполняет программу в симбиозе с процессором графическим.
Архитектурно центральный процессор (CPU) и его графический собрат (GPU) устроены по-разному. Если проводить аналогию с миром автопрома, то CPU — универсал, из тех, которые называют «сарай». Выглядит легковым авто, но при этом (с точки зрения разработчиков) «и швец, и жнец, и на дуде игрец». Выполняет роль маленького грузовика, автобуса и гипертрофированного хечбэка одновременно. Универсал, короче. Цилиндров-ядер у него немного, но они «тянут» практически любые задачи, а внушительная кэш-память способна разместить кучу данных.
А вот GPU — это спорткар. Функция одна: доставить пилота на финиш как можно быстрее. Поэтому никакой большой памяти-багажника, никаких лишних посадочных мест. Зато цилиндров-ядер в сотни раз больше, чем у CPU.
Благодаря CUDA разработчикам программ GPGPU не требуется вникать в сложности программи-
рования под такие графические движки, как DirectX и OpenGL
В отличие от центрального процессора, способного решать любую задачу, в том числе и графическую, но с усредненной производительностью, графический процессор адаптирован на высокоскоростное решение одной задачи: превращение куч полигонов на входе в кучу пикселов на выходе. Причем задачу эту можно решать параллельно на сотнях относительно простых вычислительных ядер в составе GPU.
Так какой же может быть тандем из универсала и спорткара? Работа CUDA происходит примерно так: программа выполняется на CPU до тех пор, пока в ней появляется участок кода, который можно выполнить параллельно. Тогда, вместо того, чтобы он медленно выполнялся на двух (да пусть даже и восьми) ядрах самого крутого CPU, его передают на сотни ядер GPU. При этом время выполнения этого участка сокращается в разы, а значит, сокращается и время выполнения всей программы.
Технологически для программиста ничего не меняется. Код CUDA-программ пишется на языке Си. Точнее, на особом его диалекте «С with streams» (Си с потоками). Разработанное в Стэнфорде, это расширение языка Си получило название Brook. В качестве интерфейса, передающего Brook-код на GPU, выступает драйвер видеокарты, поддерживающей CUDA. Он организует весь процесс обработки этого участка программы так, что для программиста GPU выглядит как сопроцессор CPU. Очень похоже на использование математического сопроцессора на заре персональных компьютеров. С появлением Brook, видеокарт с поддержкой CUDA и драйверов для них любой программист стал способен в своих программах обращаться к GPU. А ведь раньше этим шаманством владел узкий круг избранных, годами оттачивающих технику программирования под графические движки DirectX или OpenGL.
В бочку этого пафосного меда — дифирамбов CUDA — стоит положить ложку дегтя, то бишь ограничений. Далеко не любая задача, которую нужно запрограммировать, подходит для решения с помощью CUDA. Добиться ускорения решения рутинных офисных задач не получится, а вот доверить CUDA обсчет поведения тысячи однотипных бойцов в World of Warcraft — пожалуйста. Но это задача, высосанная из пальца. Рассмотрим же примеры того, что CUDA уже очень эффективно решает.
Труды праведные
CUDA — весьма прагматичная технология. Реализовав ее поддержку в своих видеокартах, компания nVidia весьма справедливо рассчитывала на то, что знамя CUDA будет подхвачено множеством энтузиастов как в университетской среде, так и в коммерции. Так и случилось. Проекты на базе CUDA живут и приносят пользу.
NVIDIA PhysX
Рекламируя очередной игровой шедевр, производители частенько напирают на его 3D-реалистичность. Но каким бы реальным ни был игровой 3D-мир, если элементарные законы физики, такие как тяготение, трение, гидродинамика, будут реализованы неправильно, фальшь почувствуется моментально.
Одна из возможностей физического движка NVIDIA PhysX — реалистичная работа с тканями.
Реализовать алгоритмы компьютерной симуляции базовых физических законов — дело очень трудоемкое. Наиболее известными компаниями на этом поприще являются ирландская компания Havok с ее межплатформенным физическим Havok Physics и калифорнийская Ageia — прародитель первого в мире физического процессора (PPU — Physics Processing Unit) и соответствующего физического движка PhysX. Первая из них, хотя и приобретена компанией Intel, активно трудится сейчас на поприще оптимизации движка Havok для видеокарт ATI и процессоров AMD. А вот Ageia с ее движком PhysX стала частью nVidia. При этом nVidia решила достаточно сложную задачу адаптации PhysX под технологию CUDA.
Возможным это стало благодаря статистике. Статистически было доказано, что, какой бы сложный рендеринг ни выполнял GPU, часть его ядер все равно простаивает. Именно на этих ядрах и работает движок PhysX.
Благодаря CUDA львиная доля вычислений, связанных с физикой игрового мира, стала выполняться на видеокарте. Освободившаяся мощь центрального процессора была брошена на решение других задач геймплея. Результат не заставил себя ждать. По оценкам экспертов, прирост производительности игрового процесса с PhysX, работающем, на CUDA возрос минимум на порядок. Выросло и правдоподобие реализации физических законов. CUDA берет на себя рутинный расчет реализации трения, тяготения и прочих привычных нам вещей для многомерных объектов. Теперь не только герои и их техника идеально вписываются в законы привычного нам физического мира, но и пыль, туман, взрывная волна, пламя и вода.
CUDA-версия пакета сжатия текстур NVIDIA Texture Tools 2
Нравятся реалистичные объекты в современных играх? Стоит сказать спасибо разработчикам текстур. Но чем больше реальности в текстуре, тем больше ее объем. Тем больше она занимает драгоценной памяти. Чтобы этого избежать, текстуры предварительно сжимают и динамически распаковывают по мере надобности. А сжатие и распаковка — это сплошные вычисления. Для работы с текстурами nVidia выпустила пакет NVIDIA Texture Tools. Он поддерживает эффективное сжатие и распаковку текстур стандарта DirectX (так называемый ВЧЕ-формат). Вторая версия этого пакета может похвастаться поддержкой алгоритмов сжатия BC4 и BC5, реализованных в технологии DirectX 11. Но главное то, что в NVIDIA Texture Tools 2 реализована поддержка CUDA. По оценке nVidia, это дает 12-кратный прирост производительности в задачах сжатия и распаковки текстур. А это значит, что фреймы игрового процесса будут грузиться быстрее и радовать игрока своей реалистичностью.
Пакет NVIDIA Texture Tools 2 заточен под работу с CUDA. Прирост производительности при сжатии и распаковке текстур налицо.
Использование CUDA позволяет существенно повысить эффективность видеослежки.
Обработка видеопотока в реальном времени
Как ни крути, а нынешний мир, с точки зрения соглядатайства, куда ближе к миру оруэлловского Большого Брата, чем кажется. Пристальные взгляды видеокамер ощущают на себе и водители авто, и посетители общественных мест.
Полноводные реки видеоинформации стекаются в центры ее обработки и... наталкиваются на узкое звено — человека. Именно он в большинстве случаев — последняя инстанция, следящая за видеомиром. Причем инстанция не самая эффективная. Моргает, отвлекается и норовит уснуть.
Благодаря CUDA появилась возможность реализации алгоритмов одновременного слежения за множеством объектов в видеопотоке. При этом процесс происходит в реальном масштабе времени, а видео является полноценным 30 fps. По сравнению с реализацией такого алгоритма на современных многоядерных CPU CUDA дает двух-, трехкратный прирост производительности, а это, согласитесь, немало.
Конвертирование видео, фильтрация аудио
Видеоконвертер Badaboom — первая ласточка, использующая CUDA для ускорения конвертирования.
Приятно посмотреть новинку видеопроката в FullHD-качестве и на большом экране. Но большой экран не возьмешь с собой в дорогу, а видеокодек FullHD будет икать на маломощном процессоре мобильного гаджета. На помощь приходит конвертирование. Но большинство тех, кто с ним сталкивался на практике, сетуют на длительное время конвертации. Оно и понятно, процесс рутинный, пригодный к распараллеливанию, и его выполнение на CPU не очень оптимально.
А вот CUDA с ним справляется на ура. Первая ласточка — конвертер Badaboom от компании Elevental. Разработчики Badaboom, выбрав CUDA, не просчитались. Тесты показывают, что стандартный полуторачасовый фильм на нем конвертируется в формат iPhone/iPod Touch менее чем за двадцать минут. И это при том, что при использовании только CPU этот процесс занимает больше часа.
Помогает CUDA и профессиональным меломанам. Любой из них полцарства отдаст за эффективный FIR-кроссовер — набор фильтров, разделяющих звуковой спектр на несколько полос. Процесс этот весьма трудоемкий и при большом объеме аудиоматериала заставляет звукорежиссера сходить на несколько часов «покурить». Реализация FIR-кроссовера на базе CUDA ускоряет его работу в сотни раз.
CUDA Future
Сделав технологию GPGPU реальностью, CUDA не собирается почивать на лаврах. Как это происходит повсеместно, в CUDA работает принцип рефлексии: теперь не только архитектура видеопроцессоров nVidia влияет на развитие версий CUDA SDK, а и сама технология CUDA заставляет nVidia пересматривать архитектуру своих чипов. Пример такой рефлексии — платформа nVidia ION. Ее вторая версия специально оптимизирована для решения CUDA-задач. А это означает, что даже в относительно недорогих аппаратных решениях потребители получат всю мощь и блестящие возможности CUDA.
В развитии современных процессоров намечается тенденция к постепенному увеличению количества ядер, что повышает их возможности в параллельных вычислениях. Однако уже давно имеются GPU, значительно превосходящие центральные процессоры в данном отношении. И эти возможности графических процессоров уже взяты на заметку некоторыми компаниями. Первые попытки использовать графические ускорители для нецелевых вычислений предпринимались еще с конца 90-х годов. Но только появление шейдеров стало толчком к развитию абсолютно новой технологии, и в 2003 году появилось понятие GPGPU (General-purpose graphics processing units). Немаловажную роль в развитии данной инициативы сыграл BrookGPU, который является специальным расширением для языка C. До появления BrookGPU программисты могли работать с GPU лишь через API Direct3D или OpenGL. Brook позволил разработчикам работать с привычной средой, а уже сам компилятор с помощью специальных библиотек реализовал взаимодействие с GPU на низком уровне.
Такой прогресс не мог не привлечь внимания лидеров данной индустрии - AMD и NVIDIA, которые занялись разработкой собственных программных платформ для неграфических вычислений на своих видеокартах. Никто лучше разработчиков GPU не знает в совершенстве все нюансы и особенности своих продуктов, что позволяет этим же компаниям максимально эффективно оптимизировать программный комплекс для конкретных аппаратных решений. На данный момент NVIDIA развивает платформу CUDA (Compute Unified Device Architecture), у AMD подобная технология именуется CTM (Close To Metal) или AMD Stream Computing. Мы рассмотрим некоторые возможности CUDA и на практике оценим вычислительные возможности графического чипа G92 видеокарты GeForce 8800 GT.
Но прежде рассмотрим некоторые нюансы выполнения расчетов при помощи графических процессоров. Основное преимущество их заключается в том, что графический чип изначально проектируется под выполнение множества потоков, а каждое ядро обычного CPU выполняет поток последовательных инструкций. Любой современный GPU является мультипроцессором, состоящим из нескольких вычислительных кластеров, с множеством ALU в каждом. Самый мощный современный чип GT200 состоит из 10 таких кластеров, на каждый из которых приходится 24 потоковых процессора. У тестируемой видеокарты GeForce 8800 GT на базе чипа G92 семь больших вычислительных блока по 16 потоковых процессоров. CPU используют SIMD блоки SSE для векторных вычислений (single instruction multiple data - одна инструкция выполняется над многочисленными данными), что требует трансформации данных в 4х векторы. GPU скалярно обрабатывает потоки, т.е. одна инструкция применяется над несколькими потоками (SIMT - single instruction multiple threads). Это избавляет разработчиков от преобразования данных в векторы, и допускает произвольные ветвления в потоках. Каждый вычислительный блок GPU имеет прямой доступ к памяти. Да и пропускная способность видеопамяти выше, благодаря использованию нескольких раздельных контроллеров памяти (на топовом G200 это 8 каналов по 64-бит) и высоких рабочих частот.
В целом, в определенных задачах при работе с большими объемами данных GPU оказываются намного быстрее CPU. Ниже вы видите иллюстрацию этого утверждения:
На диаграмме изображена динамика роста производительности CPU и GPU начиная с 2003 года. Данные эти любит приводить в качестве рекламы в своих документах NVIDIA, но они являются лишь теоретической выкладкой и на самом деле отрыв, конечно же, может оказаться намного меньше.
Но как бы там ни было, есть огромный потенциал графических процессоров, который можно использовать, и который требует специфического подхода к разработке программных продуктов. Все это реализовано в аппаратно-программной среде CUDA, которая состоит из нескольких программных уровней - высокоуровневый CUDA Runtime API и низкоуровневый CUDA Driver API.

CUDA использует для программирования стандартный язык C, что является одним из основных ее преимуществ для разработчиков. Изначально CUDA включает библиотеки BLAS (базовый пакет программ линейной алгебры) и FFT (расчёт преобразований Фурье). Также CUDA имеет возможность взаимодействия с графическими API OpenGL или DirectX, возможность разработки на низком уровне, характеризуется оптимизированным распределением потоков данных между CPU и GPU. Вычисления CUDA выполняются одновременно с графическими, в отличие от аналогичной платформы AMD, где для расчетов на GPU вообще запускается специальная виртуальная машина. Но такое «сожительство» чревато и возникновением ошибок в случае создания большой нагрузки графическим API при одновременной работе CUDA - ведь графические операции имеют все же более высокий приоритет. Платформа совместима с 32- и 64-битными операционными системами Windows XP, Windows Vista, MacOS X и различными версиями Linux. Платформа открытая и на сайте, кроме специальных драйверов для видеокарты, можно загрузить программные пакеты CUDA Toolkit, CUDA Developer SDK, включающие компилятор, отладчик, стандартные библиотеки и документацию.
Что же касается практической реализации CUDA, то длительное время эта технология использовалась лишь для узкоспециализированных математических вычислений в области физики элементарных частиц, астрофизики, медицины или прогнозирования изменений финансового рынка и т.п. Но данная технология становится постепенно ближе и к рядовым пользователям, в частности появляются специальные плагины для Photoshop, которые могут задействовать вычислительную мощность GPU. На специальной страничке можно изучить весь список программ, использующих возможности NVIDIA CUDA.
В качестве практических испытаний новой технологии на видеокарте MSI NX8800GT-T2D256E-OC мы воспользуемся программой TMPGEnc. Данный продукт является коммерческим (полная версия стоит $100), но к видеокартам MSI он поставляется в качестве бонуса в trial-версии сроком на 30 дней. Скачать данную версию можно и с сайта разработчика, но для установки TMPGEnc 4.0 XPress MSI Special Edition необходим оригинальный диск с драйверами от карты MSI - без него программа не инсталлируется.
Для отображения максимально полной информации о вычислительных возможностях в CUDA и сравнения с другими видеоадаптерами можно использовать специальную утилиту CUDA-Z. Вот какую информацию она выдает о нашей видеокарте GeForce 8800GT:
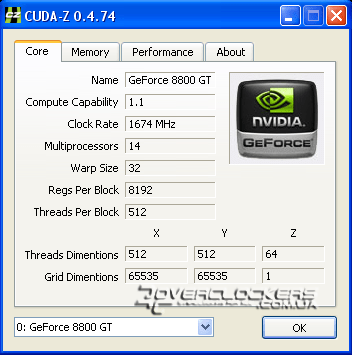


Относительно референсных моделей наш экземпляр работает на более высоких частотах: растровый домен на 63 МГц выше номинала, а шейдерные блоки быстрее на 174 МГц, память - на 100 МГц.
Мы сравним скорость конвертации одного и того же HD-видео при расчетах только с помощью CPU и при дополнительной активации CUDA в программе TMPGEnc на следующей конфигурации:
- Процессор: Pentium Dual-Core E5200 2,5 ГГц;
- Материнская плата: Gigabyte P35-S3;
- Память: 2х1GB GoodRam PC6400 (5-5-5-18-2T)
- Видеокарта: MSI NX8800GT-T2D256E-OC;
- Жесткий диск: 320GB WD3200AAKS;
- Блок питания: CoolerMaster eXtreme Power 500-PCAP;
- Операционная система: Windows XP SP2;
- TMPGEnc 4.0 XPress 4.6.3.268;
- Драйвера видеокарты: ForceWare 180.60.

Кодирование осуществлялось с помощью кодека DivX 6.8.4. В настройках качества этого кодека все значения оставлены по умолчанию, multithreading включен.

Поддержка многопоточности в TMPGEnc изначально включена во вкладке настроек CPU/GPU. В этом же разделе активируется и CUDA.

Как видно по приведенному скриншоту, активирована обработка фильтров с помощью CUDA, а аппаратный видеодекодер не включен. В документации к программе предупреждается, что активация последнего параметра приводит к увеличению времени обработки файла.
По итогам проведенных тестов получены следующие данные:

При частоте процессора 4 ГГц с активацией CUDA мы выиграли всего пару секунд (или 2%), что не особо впечатляет. А вот на более низкой частоте прирост от активации данной технологии позволяет сэкономить уже около 13% времени, что будет довольно ощутимо при обработке больших файлов. Но все равно результаты не столь впечатляющие, как ожидалось.
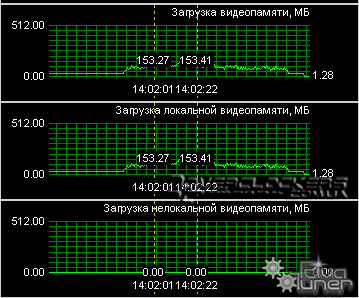
В программе TMPGEnc есть индикатор загрузки CPU и CUDA, в данной тестовой конфигурации он показывал загрузку центрального процессора примерно на 20%, а графического ядра на оставшиеся 80%. В итоге у нас те же 100%, что и при конвертации без CUDA и разницы по времени вообще может и не быть (но она все-таки есть). Небольшой объем памяти в 256 MB так же не является сдерживающим фактором. Судя по показаниям RivaTuner, в процессе работы использовалось не более 154 MB видеопамяти.
Выводы
Программа TMPGEnc является одной из тех, кто вводит технологию CUDA в массы. Использование GPU в данной программе позволяет ускорить процесс обработки видео и значительно разгрузить центральный процессор, что позволит пользователю комфортно заниматься и другими задачами в это же время. В нашем конкретном примере видеокарта GeForce 8800GT 256MB незначительно улучшила временные показатели при конвертации видео на базе разогнанного процессора Pentium Dual-Core E5200. Но отчетливо видно, что при снижении частоты увеличивается прирост от активации CUDA, на слабых процессорах прирост от ее использования будет намного больше. На фоне такой зависимости вполне логично предположить что и при увеличении нагрузки (например, использование очень большого количества дополнительных видео-фильтров) результаты системы с CUDA будут выделяется более значимой дельтой разницы затраченного времени на процесс кодирования. Также не стоит забывать, что и G92 на данный момент не самый мощный чип, и более современные видеокарты обеспечат значительно более высокую производительность в подобных приложениях. Однако в процессе работы приложения GPU загружен не полностью и, вероятно, распределение нагрузки зависит от каждой конфигурации отдельно, а именно от связки процессор/видеокарта, что в итоге может дать и больший (или меньший) прирост в процентном соотношении от активации CUDA. В любом случае, тем, кто работает с большими объемами видеоданных, такая технология все равно позволит значительно сэкономить свое время.
Правда, CUDA еще не обрела повсеместную популярность, качество программного обеспечения, работающего с этой технологией, требует доработок. В рассмотренной нами программе TMPGEnc 4.0 XPress данная технология не всегда работала. Один и тот же ролик можно было перекодировать несколько раз, а потом вдруг, при следующем запуске, загрузка CUDA уже была равна 0%. И это явление носило совершенно случайный характер на абсолютно разных операционных системах. Также рассмотренная программа отказывалась использовать CUDA при кодировании в формат XviD, но с популярным кодеком DivX никаких проблем не было.
В итоге пока технология CUDA позволяет ощутимо увеличить производительность персональных компьютеров лишь в определенных задачах. Но сфера применения подобной технологии будет расширяться, а процесс наращивания количества ядер в обычных процессорах свидетельствует о росте востребованности параллельных многопоточных вычислений в современных программных приложениях. Не зря в последнее время все лидеры индустрии загорелись идеей объединения CPU и GPU в рамках одной унифицированной архитектуры (вспомнить хотябы разрекламированный AMD Fusion). Возможно CUDA это один из этапов в процессе данного объединения.
Благодарим следующие компании за предоставленное тестовое оборудование:
Ядра CUDA – условное обозначение скалярных вычислительных блоков в видео-чипах NVidia , начиная с G 80 (GeForce 8 xxx, Tesla C-D-S870 , FX4 /5600 , 360M ). Сами чипы являются производными архитектуры. К слову, потому компания NVidia так охотно взялась за разработку собственных процессоров Tegra Series , основанных тоже на RISC архитектуре. Опыт работы с данными архитектурами очень большой.
CUDA ядро содержит в себе один один векторный и один скалярный юнит, которые за один такт выполняют по одной векторной и по одной скалярной операции, передавая вычисления другому мультипроцессору, либо в для дальнейшей обработки. Массив из сотен и тысяч таких ядер, представляет из себя значительную вычислительную мощность и может выполнять различные задачи в зависимости от требований, при наличии определённого софта поддерживающего . Применение может быть разнообразным: декодирование видеопотока, ускорение 2D/3D графики, облачные вычисления, специализированные математические анализы и т.д.
Довольно часто, объединённые профессиональные карты NVidia Tesla и NVidia Quadro , являются костяком современных суперкомпьютеров.
CUDA — ядра не претерпели каких либо значимых изменений со времён G 80 , но увеличивается их количество (совместно с другими блоками — ROP , Texture Units & etc) и эффективность параллельных взаимодействий друг с другом (улучшаются модули Giga Thread ).

К примеру:
GeForce
GTX 460 — 336 CUDA ядер
GTX 580 — 512 CUDA ядер
8800GTX — 128 CUDA ядер
От количества потоковых процессоров (CUDA ), практически пропорционально увеличивается производительность в шейдерных вычислениях (при равномерном увеличении количества и других элементов).
Начиная с чипа GK110 (NVidia GeForce GTX 680) — CUDA ядра теперь не имеют удвоенную частоту, а общую со всеми остальными блоками чипа. Вместо этого было увеличено их количество примерно в три раза в сравнении с предыдущим поколением G110 .
Технология CUDA
Владимир Фролов, [email protected]
Аннотация
Статья рассказывает о технологии CUDA, позволяющей программисту использовать видеокарты в качестве мощных вычислительных единиц. Инструменты, предоставленные Nvidia, дают возможность писать программы для графического процессора (GPU) на подмножестве языка С++. Это избавляет программиста от необходимости использования шейдеров и понимания процесса работы графического конвейера. В статье приведены примеры программирования с использованием CUDA и различные приемы оптимизации.
1. Введение
Развитие вычислительных технологий последние десятки лет шло быстрыми темпами. Настолько быстрыми, что уже сейчас разработчики процессоров практически подошли к так называемому «кремниевому тупику». Безудержный рост тактовой частоты стал невозможен в силу целого ряда серьезных технологических причин.
Отчасти поэтому все производители современных вычислительных систем идут в сторону увеличения числа процессоров и ядер, а не увеличивают частоту одного процессора. Количество ядер центрального процессора (CPU) в передовых системах сейчас уже равняется 8.
Другая причина- относительно невысокая скорость работы оперативной памяти. Как бы быстро не работал процессор, узкими местами, как показывает практика, являются вовсе не арифметические операции, а именно неудачные обращения к памяти- кэш-промахи.
Однако если посмотреть в сторону графических процессоров GPU (Graphics Processing Unit), то там по пути параллелизма пошли гораздо раньше. В сегодняшних видеокартах, например в GF8800GTX, число процессоров может достигать 128. Производительность подобных систем при умелом их программировании может быть весьма значительной (рис. 1).
Рис. 1. Количество операций с плавающей точкой для CPU и GPU
Когда первые видеокарты только появились в продаже, они представляли собой достаточно простые (по сравнению с центральным процессором) узкоспециализированные устройства, предназначенные для того чтобы снять с процессора нагрузку по визуализации двухмерных данных. С развитием игровой индустрии и появлением таких трехмерных игр как Doom (рис. 2) и Wolfenstein 3D (рис. 3) возникла необходимость в 3D визуализации.


Рисунки 2,3. Игры Doom и Wolfenstein 3D
Со времени создания компанией 3Dfx первых видеокарт Voodoo, (1996 г.) и вплоть до 2001 года в GPU был реализован только фиксированный набор операций над входными данными.
У программистов не было никакого выбора в алгоритме визуализации, и для повышения гибкости появились шейдеры- небольшие программы, выполняющиеся видеокартой для каждой вершины либо для каждого пиксела. В их задачи входили преобразования над вершинами и затенение- расчет освещения в точке, например по модели Фонга.
Хотя в настоящий момент шейдеры получили очень сильное развитие, следует понимать, что они были разработаны для узкоспециализированных задач трехмерных преобразований и растеризации. В то время как GPU развиваются в сторону универсальных многопроцессорных систем, языки шейдеров остаются узкоспециализированными.
Их можно сравнить с языком FORTRAN в том смысле, что они, как и FORTRAN, были первыми, но предназначенными для решения лишь одного типа задач. Шейдеры малопригодны для решения каких-либо других задач, кроме трехмерных преобразований и растеризации, как и FORTRAN не удобен для решения задач, не связанных с численными расчетами.
Сегодня появилась тенденция нетрадиционного использования видеокарт для решения задач в областях квантовой механики, искусственного интеллекта, физических расчетов, криптографии, физически корректной визуализации, реконструкции по фотографиям, распознавания и.т.п. Эти задачи неудобно решать в рамках графических API (DirectX, OpenGL), так как эти API создавались совсем для других применений.
Развитие программирования общего назначения на GPU (General Programming on GPU, GPGPU) логически привело к возникновению технологий, нацеленных на более широкий круг задач, чем растеризация. В результате компанией Nvidia была создана технология Compute Unified Device Architecture (или сокращенно CUDA), а конкурирующей компанией ATI - технология STREAM.
Следует заметить, что на момент написания этой статьи, технология STREAM сильно отставала в развитии от CUDA, и поэтому здесь она рассматриваться не будет. Мы сосредоточимся на CUDA - технологии GPGPU, позволяющей писать программы на подмножестве языка C++.
2. Принципиальная разница между CPU и GPU
Рассмотрим вкратце некоторые существенные отличия между областями и особенностями применений центрального процессора и видеокарты.
2.1. Возможности
CPU изначально приспособлен для решения задач общего плана и работает с произвольно адресуемой памятью. Программы на CPU могут обращаться напрямую к любым ячейкам линейной и однородной памяти.
Для GPU это не так. Как вы узнаете, прочитав эту статью, в CUDA имеется целых 6 видов памяти. Читать можно из любой ячейки, доступной физически, но вот записывать – не во все ячейки. Причина заключается в том, что GPU в любом случае представляет собой специфическое устройство, предназначенное для конкретных целей. Это ограничение введено ради увеличения скорости работы определенных алгоритмов и снижения стоимости оборудования.
2.2. Быстродействие памяти
Извечная проблема большинства вычислительных систем заключена в том, что память работает медленнее процессора. Производители CPU решают ее путем введения кэшей. Наиболее часто используемые участки памяти помещается в сверхоперативную или кэш-память, работающую на частоте процессора. Это позволяет сэкономить время при обращении к наиболее часто используемым данным и загрузить процессор собственно вычислениями.
Заметим, что кэши для программиста фактически прозрачны. Как при чтении, так и при записи данные не попадают сразу в оперативную память, а проходят через кэши. Это позволяет, в частности, быстро считывать некоторое значение сразу же после записи .
На GPU (здесь подразумевается видеокарты GF восьмой серии) кэши тоже есть, и они тоже важны, но этот механизм не такой мощный, как на CPU. Во-первых, кэшируется не все типы памяти, а во-вторых, кэши работают только на чтение.
На GPU медленные обращения к памяти скрывают, используя параллельные вычисления. Пока одни задачи ждут данных, работают другие, готовые к вычислениям. Это один из основных принципов CUDA, позволяющих сильно поднять производительность системы в целом .
3. Ядро CUDA
3.1. Потоковая модель
Вычислительная архитектура CUDA основана на концепции одна команда на множество данных (Single Instruction Multiple Data , SIMD) и понятии мультипроцессора .
Концепция SIMD подразумевает, что одна инструкция позволяет одновременно обработать множество данных. Например, команда addps в процессоре Pentium 3 и в более новых моделях Pentium позволяет складывать одновременно 4 числа с плавающей точкой одинарной точности.
Мультипроцессор - это многоядерный SIMD процессор, позволяющий в каждый определенный момент времени выполнять на всех ядрах только одну инструкцию. Каждое ядро мультипроцессора скалярное, т.е. оно не поддерживает векторные операции в чистом виде.
Перед тем как продолжить, введем пару определений. Отметим, что под устройством и хостом в данной статье будет пониматься совсем не то, к чему привыкло большинство программистов. Мы будем пользоваться такими терминами для того чтобы избежать расхождений с документацией CUDA.
Под устройством (device) в нашей статье мы будем понимать видеоадаптер, поддерживающий драйвер CUDA, или другое специализированное устройство, предназначенное для исполнения программ, использующих CUDA (такое, например, как NVIDIA Tesla ). В нашей статье мы рассмотрим GPU только как логическое устройство, избегая конкретных деталей реализации.
Хостом (host ) мы будем называть программу в обычной оперативной памяти компьютера, использующую CPU и выполняющую управляющие функции по работе с устройством.
Фактически, та часть вашей программы, которая работает на CPU - это хост, а ваша видеокарта - устройство. Логически устройство можно представить как набор мультипроцессоров (рис. 4) плюс драйвер CUDA.

Рис. 4. Устройство
Предположим, что мы хотим запустить на нашем устройстве некую процедуру в N потоках (то есть хотим распараллелить ее работу). В соответствии с документацией CUDA, назовем эту процедуру ядром.
Особенностью архитектуры CUDA является блочно-сеточная организация, необычная для многопоточных приложений (рис. 5). При этом драйвер CUDA самостоятельно распределяет ресурсы устройства между потоками.

Рис. 5. Организация потоков
На рис. 5. ядро обозначено как Kernel. Все потоки, выполняющие это ядро, объединяются в блоки (Block), а блоки, в свою очередь, объединяются в сетку (Grid).
Как видно на рис 5, для идентификации потоков используются двухмерные индексы. Разработчики CUDA предоставили возможность работать с трехмерными, двухмерными или простыми (одномерными) индексами, в зависимости от того, как удобнее программисту.
В общем случае индексы представляют собой трехмерные векторы. Для каждого потока будут известны: индекс потока внутри блока threadIdx и индекс блока внутри сетки blockIdx. При запуске все потоки будут отличаться только этими индексами. Фактически, именно через эти индексы программист осуществляет управление, определяя, какая именно часть его данных обрабатывается в каждом потоке.
Ответ на вопрос, почему разработчики выбрали именно такую организацию, нетривиален. Одна из причин состоит в том, что один блок гарантировано исполняется на одном мультипроцессоре устройства, но один мультипроцессор может выполнять несколько различных блоков. Остальные причины прояснятся дальше по ходу статьи.
Блок задач (потоков) выполняется на мультипроцессоре частями, или пулами, называемыми warp. Размер warp на текущий момент в видеокартах с поддержкой CUDA равен 32 потокам. Задачи внутри пула warp исполняются в SIMD стиле, т.е. во всех потоках внутри warp одновременно может выполняться только одна инструкция .
Здесь следует сделать одну оговорку. В архитектурах, современных на момент написания этой статьи, количество процессоров внутри одного мультипроцессора равно 8, а не 32. Из этого следует, что не весь warp исполняется одновременно, он разбивается на 4 части, которые выполняются последовательно (т.к. процессоры скалярные).
Но, во-первых, разработчики CUDA не регламентируют жестко размер warp. В своих работах они упоминают параметр warp size, а не число 32. Во-вторых, с логической точки зрения именно warp является тем минимальным объединением потоков, про который можно говорить, что все потоки внутри него выполняются одновременно - и при этом никаких допущений относительно остальной системы сделано не будет .
3.1.1. Ветвления
Сразу же возникает вопрос: если в один и тот же момент времени все потоки внутри warp исполняют одну и ту же инструкцию, то как быть с ветвлениями? Ведь если в коде программы встречается ветвление, то инструкции будут уже разные. Здесь применяется стандартное для SIMD программирования решение (рис 6).

Рис. 6. Организация ветвления в SIMD
Пусть имеется следующий код:
if(cond) B;
В случае SISD (Single Instruction Single Data) мы выполняем оператор A, проверяем условие, затем выполняем операторы B и D (если условие истинно).
Пусть теперь у нас есть 10 потоков, исполняющихся в стиле SIMD. Во всех 10 потоках мы выполняем оператор A, затем проверяем условие cond и оказывается, что в 9 из 10 потоках оно истинно, а в одном потоке - ложно.
Понятно, что мы не можем запустить 9 потоков для выполнения оператора B, а один оставшийся- для выполнения оператора C, потому что одновременно во всех потоках может исполняться только одна инструкция. В этом случае нужно поступить так: сначала «убиваем» отколовшийся поток так, чтобы он не портил ничьи данные, и выполняем 9 оставшихся потоков. Затем «убиваем» 9 потоков, выполнивших оператор B, и проходим один поток с оператором C. После этого потоки опять объединяются и выполняют оператор D все одновременно .
Получается печальный результат: мало того что ресурсы процессоров расходуются на пустое перемалывание битов в отколовшихся потоках, так еще, что гораздо хуже, мы будем вынуждены в итоге выполнить ОБЕ ветки.
Однако не все так плохо, как может показаться на первый взгляд. К очень большому плюсу технологии можно отнести то, что эти фокусы выполняются динамически драйвером CUDA и для программиста они совершенно прозрачны. В то же время, имея дело с SSE командами современных CPU (именно в случае попытки выполнения 4 копий алгоритма одновременно), программист сам должен заботиться о деталях: объединять данные по четверкам, не забывать о выравнивании, и вообще писать на низком уровне, фактически как на ассемблере .
Из всего вышесказанного следует один очень важный вывод. Ветвления не являются причиной падения производительности сами по себе. Вредны только те ветвления, на которых потоки расходятся внутри одного пула потоков warp. При этом если потоки разошлись внутри одного блока, но в разных пулах warp, или внутри разных блоков, это не оказывает ровным счетом никакого эффекта.
3.1.2. Взаимодействие между потоками
На момент написания этой статьи любое взаимодействие между потоками (синхронизация и обмен данными) было возможно только внутри блока. То есть между потоками разных блоков нельзя организовать взаимодействие, пользуясь лишь документированными возможностями.
Что касается недокументированных возможностей, ими пользоваться крайне не рекомендуется. Причина этого в том, что они опираются на конкретные аппаратные особенности той или иной системы.
Синхронизация всех задач внутри блока осуществляется вызовом функции __synchtreads. Обмен данными возможен через разделяемую память, так как она общая для всех задач внутри блока .
3.2. Память
В CUDA выделяют шесть видов памяти (рис. 7). Это регистры, локальная, глобальная, разделяемая, константная и текстурная память.
Такое обилие обусловлено спецификой видеокарты и первичным ее предназначением, а также стремлением разработчиков сделать систему как можно дешевле, жертвуя в различных случаях либо универсальностью, либо скоростью.

Рис. 7. Виды памяти в CUDA
3.2.0. Регистры
По возможности компилятор старается размещать все локальные переменные функций в регистрах. Доступ к таким переменным осуществляется с максимальной скоростью. В текущей архитектуре на один мультипроцессор доступно 8192 32-разрядных регистра. Для того чтобы определить, сколько доступно регистров одному потоку, надо разделить это число (8192) на размер блока (количество потоков в нем).
При обычном разделении в 64 потока на блок получается всего 128 регистров (существуют некие объективные критерии, но 64 подходит в среднем для многих задач). Реально, 128 регистров nvcc никогда не выделит. Обычно он не дает больше 40, а остальные переменные попадпют в локальную память. Так происходит потому что на одном мультипроцессоре может исполняться несколько блоков. Компилятор старается максимизировать число одновременно работающих блоков. Для большей большей эффективности надо стараться занимать меньше чем 32 регистра. Тогда теоретически может быть запущено 4 блока (8 warp-ов, если 64 треда в одном блоке) на одном мультипроцессоре. Однако здесь еще следует учитывать объем разделяемой памяти, занимаемой потоками, так как если один блок занимает всю разделяемую память, два таких блока не могут выполняться на мультипроцессоре одновременно .
3.2.1. Локальная память
В случаях, когда локальные данные процедур занимают слишком большой размер, или компилятор не может вычислить для них некоторый постоянный шаг при обращении, он может поместить их в локальную память. Этому может способствовать, например, приведение указателей для типов разных размеров.
Физически локальная память является аналогом глобальной памяти, и работает с той же скоростью. На момент написания статьи не было никаких механизмов, позволяющих явно запретить компилятору использование локальной памяти для конкретных переменных. Так как проконтролировать локальную память довольно трудно, лучше не использовать ее вовсе (см. раздел 4 «Рекомендации по оптимизации»).
3.2.2. Глобальная память
В документации CUDA в качестве одного из основных достижений технологии приводится возможность произвольной адресации глобальной памяти. То есть можно читать из любой ячейки памяти, и писать можно тоже в произвольную ячейку (на GPU это обычно не так).
Однако за универсальность в данном случае приходится расплачиваться скоростью. Глобальная память не кэшируется. Она работает очень медленно, количество обращений к глобальной памяти следует в любом случае минимизировать.
Глобальная память необходима в основном для сохранения результатов работы программы перед отправкой их на хост (в обычную память DRAM). Причина этого в том, что глобальная память - единственный вид памяти, куда можно что-то записывать.
Переменные, объявленные с квалификатором __global__, размещаются в глобальной памяти. Глобальную память также можно выделить динамически, вызвав функцию cudaMalloc(void* mem, int size) на хосте. Из устройства эту функцию вызывать нельзя. Отсюда следует, что распределением памяти должна заниматься программа-хост, работающая на CPU. Данные с хоста можно отправлять в устройство вызовом функции cudaMemcpy:
cudaMemcpy(void* gpu_mem, void* cpu_mem, int size, cudaMemcpyHostToDevice);
Точно таким же образом можно проделать и обратную процедуру:
cudaMemcpy(void* cpu_mem, void* gpu_mem, int size, cudaMemcpyDeviceToHost);
Этот вызов тоже осуществляется с хоста.
При работе с глобальной памятью важно соблюдать правило коалесинга (coalescing). Основная идея в том, что треды должны обращаться к последоваетльным ячейкам памяти, причем 4,8 или 16 байтовым. При этом, самый первый тред должен обращаться по адресу, выровненному на границу соответственно 4,8 или 16 байт. Адреса, возвращаемые cudaMalloc выровнены как минимум по границе 256 байт.
3.2.3. Разделяемая память
Разделяемая память - это некэшируемая, но быстрая память. Ее и рекомендуется использовать как управляемый кэш. На один мультипроцессор доступно всего 16KB разделяемой памяти. Разделив это число на количество задач в блоке, получим максимальное количество разделяемой памяти, доступной на один поток (если планируется использовать ее независимо во всех потоках).
Отличительной чертой разделяемой памяти является то, что она адресуется одинаково для всех задач внутри блока (рис. 7). Отсюда следует, что ее можно использовать для обмена данными между потоками только одного блока.
Гарантируется, что во время исполнения блока на мультипроцессоре содержимое разделяемой памяти будет сохраняться. Однако после того как на мультипроцессоре сменился блок, не гарантируется, что содержимое старого блока сохранилось. Поэтому не стоит пытаться синхронизировать задачи между блоками, оставляя в разделяемой памяти какие-либо данные и надеясь на их сохранность.
Переменные, объявленные с квалификатором __shared__, размещаются в разделяемой памяти.
Shared__ float mem_shared;
Следует еще раз подчеркнуть, что разделяемая память для блока одна. Поэтому если нужно использовать ее просто как управляемый кэш, следует обращаться к разным элементам массива, например, так:
float x = mem_shared;
Где threadIdx.x - индекс x потока внутри блока.
3.2.4. Константная память
Константная память кэшируется, как это видно на рис. 4. Кэш существует в единственном экземпляре для одного мультипроцессора, а значит, общий для всех задач внутри блока. На хосте в константную память можно что-то записать, вызвав функцию cudaMemcpyToSymbol. Из устройства константная память доступна только для чтения.
Константная память очень удобна в использовании. Можно размещать в ней данные любого типа и читать их при помощи простого присваивания.
#define N 100
Constant__ int gpu_buffer[N];
void host_function()
int cpu_buffer[N];
cudaMemcpyToSymbol(gpu_buffer, cpu_buffer, sizeof(int )*N);
// __global__ означает, что device_kernel - ядро, которое может быть запущено на GPU
Global__ void device_kernel()
int a = gpu_buffer;
int b = gpu_buffer + gpu_buffer;
// gpu_buffer = a; ОШИБКА! константная память доступна только для чтения
Так как для константной памяти используется кэш, доступ к ней в общем случае довольно быстрый. Единственный, но очень большой недостаток константной памяти заключается в том, что ее размер составляет всего 64 Kбайт (на все устройство). Из этого следует, что в контекстной памяти имеет смысл хранить лишь небольшое количество часто используемых данных.
3.2.5. Текстурная память
Текстурная память кэшируется (рис. 4). Для каждого мультипроцессора имеется только один кэш, а значит, этот кэш общий для всех задач внутри блока.
Название текстурной памяти (и, к сожалению, функциональность) унаследовано от понятий «текстура» и «текстурирование». Текстурирование - это процесс наложения текстуры (просто картинки) на полигон в процессе растеризации. Текстурная память оптимизирована под выборку 2D данных и имеет следующие возможности:
быстрая выборка значений фиксированного размера (байт, слово, двойное или учетверенное слово) из одномерного или двухмерного массива;
нормализованная адресация числами типа float в интервале . Затем можно их выбирать, используя нормализованную адресацию. Результирующим значением будетет слово типа float4, отображенное в интервал ;
CudaMalloc((void**) &gpu_memory, N*sizeof (uint4 )); // выделим память в GPU
// настройка параемтров текстуры texture
Texture.addressMode = cudaAddressModeWrap; // режим Wrap
Texture.addressMode = cudaAddressModeWrap;
Texture.filterMode = cudaFilterModePoint; // ближайшеезначение
Texture.normalized = false; // не использовать нормализованную адресацию
CudaBindTexture
(0,
texture
,
gpu
_
memory
,
N
) // отныне эта память будет считаться текстурной
CudaMemcpy (gpu _ memory , cpu _ buffer , N * sizeof (uint 4), cudaMemcpyHostToDevice ); // копируем данные на GPU
// __global__ означает, что device_kernel - ядро, которое нужно распараллелить
Global__ void device_kernel()
uint4 a = tex1Dfetch(texture,0); // можно выбирать данные только таким способом!
uint4 b = tex1Dfetch(texture,1);
int c = a.x * b.y;
...
3.3. Простой пример
В качестве простого примера предлагается рассмотреть программу cppIntegration из CUDA SDK. Она демонстрирует приемы работы с CUDA, а также использование nvcc (специальный компилятор подмножества С++ от Nvidia) в сочетании с MS Visual Studio, что сильно упрощает разработку программ на CUDA.
4.1. Правильно проводите разбиение вашей задачи
Не все задачи подходят для SIMD архитектур. Если ваша задача для этого не пригодна, возможно, не стоит использовать GPU. Но если вы твердо решили использовать GPU, нужно стараться разбить алгоритм на такие части, чтобы они могли эффективно выполняться в стиле SIMD. Если нужно - измените алгоритм для решения вашей задачи, придумайте новый - тот, который хорошо бы ложился на SIMD. Как пример подходящей области использования GPU можно привести реализацию пирамидального сложения элементов массива .
4.2. Выбор типа памяти
Помещайте свои данные в текстурную или константную память, если все задачи одного блока обращаются к одному и тому же участку памяти или к близко расположенным участкам. Двухмерные данные могут быть эффективно обработаны при помощи функций text2Dfetch и text2D. Текстурная память специально оптимизирована под двухмерную выборку.
Используйте глобальную память в сочетании с разделяемой памятью, если все задачи обращаются бессистемно к разным, далеко расположенным друг от друга участкам памяти (с сильно различными адресами или координатами, если это 2D/3D данные).
глобальная память => разделяемая память
Syncthreads();
Обработать данные в разделяемой памяти
Syncthreads();
глобальная память <= разделяемая память
4.3. Включите счетчики памяти
Флаг компилятора --ptxas-options=-v позволяет точно сказать, сколько и какой памяти (регистров, разделяемой, локальной, константной) вы используете. Если компилятор использует локальную память, вы точно знаете об этом. Анализ данных о количестве и типах используемой памяти может сильно помочь вам при оптимизации программы.
4.4. Старайтесь минимизировать использование регистров и разделяемой памяти
Чем больше ядро использует регистров или разделяемой памяти, тем меньше потоков (вернее warp-ов) одновременно могут выполняться на мультипроцессоре, т.к. ресурсы мультипроцессора ограничены. Поэтому небольшое увеличение занятости регистров или разделяемой памяти может приводить в некоторых случаях к падению производительности в два раза - именно из-за того, что теперь ровно в два раза меньше warp-ов одновременно исполняются на мультипроцессоре.
4.5. Разделяемая память вместо локальной
Если компилятор Nvidia по какой-то причине расположил данные в локальной памяти (обычно это заметно по очень сильному падению производительности в местах, где ничего ресурсоемкого нет), выясните, какие именно данные попали в локальную память, и поместите их в разделяемую память (shared memory).
Зачастую компилятор располагает переменную в локальной памяти, если она используется не часто. Например, это некий аккумулятор, где вы накапливаете значение, рассчитывая что-то в цикле. Если цикл большой по объему кода (но не по времени выполнения!), то компилятор может поместить ваш аккумулятор в локальную память, т.к. он используется относительно редко, а регистров мало. Потеря производительности в этом случае может быть заметной.
Если же вы действительно редко используете переменную - лучше явным образом поместить ее в глобальную память.
Хотя автоматическое размещение компилятором таких переменных в локальной памяти может показаться удобным, на самом деле это не так. Непросто будет найти узкое место при последующих модификациях программы, если переменная начнет использоваться чаще. Компилятор может перенести такую переменную в регистровую память, а может и не перенести. Если же модификатор __global__ будет указан явно, программист скорее обратит на это внимание.
4.6. Разворачивание циклов
Разворачивание циклов представляет собой стандартный прием повышения производительности во многих системах. Суть его в том, чтобы на каждой итерации выполнять больше действий, уменьшив таким способом общее число итераций, а значит и количество условных переходов, которые должен будет выполнить процессор .
Вот как можно развернуть цикл нахождения суммы массива (например, целочисленного):
int a[N]; int summ;
for
(int
i=0;i Разумеется, циклы можно развернуть и вручную (как показано выше), но это малопроизводительный труд. Гораздо лучше использовать шаблоны С++ в сочетание со встраиваемыми функциями. template
class
ArraySumm Device__ static T exec(const
T* arr) { return
arr + ArraySumm template
class
ArraySumm<0,T> Device__ static
T exec(const
T* arr) { return 0; } for
(int
i=0;i summ+= ArraySumm<4,int>::exec(a); Следует отметить одну интересную особенность компилятора nvcc. Компилятор всегда будет встраивать функции типа __device__ по умолчанию (чтобы это отменить, существует специальная директива __noinline__) . Следовательно, можно быть уверенным в том, что пример, подобный приведенному выше, развернется в простую последовательность операторов, и ни в чем не будет уступать по эффективности коду, написанному вручную. Однако в общем случае (не nvcc) в этом уверенным быть нельзя, так как inline представляет собой лишь указание компилятору, которое он может проигнорировать. Поэтому не гарантируется, что ваши функции будут встраиваться. Выравнивайте структуры данных по 16-байтовой границе. В этом случае компилятор сможет использовать для них специальные инструкции, выполняющие загрузку данных сразу по 16 байт. Если структура занимает 8 байт или меньше, можно выравнивать ее по 8 байт. Но в этом случае можно выбрать сразу две переменные за один раз, объединив две 8-байтовые переменные в структуру с помощью union или приведения указателей. Приведением следует пользоваться осторожно, так как компилятор может поместить данные в локальную память, а не в регистры. Разделяемая память организована в виде 16 (всего-то!) банков памяти с шагом в 4 байта. Во время выполнения пула потоков warp на мультипроцессоре, он делится на две половинки (если warp-size = 32) по 16 потоков, которые осуществляют доступ к разделяемой памяти по очереди. Задачи в разных половинах warp не конфликтуют по разделяемой памяти. Из-за того что задачи одной половинки пула warp будут обращаться к одинаковым банкам памяти, возникнут коллизии и, как следствие, падение производительности. Задачи в пределах одной половинки warp могут обращаться к различным участкам разделяемой памяти с определенным шагом. Оптимальные шаги - 4, 12, 28, ..., 2^n-4 байт (рис. 8). Рис. 8. Оптимальные шаги.
Не оптимальные шаги – 1, 8, 16, 32, ..., 2^n байт (рис. 9). Рис. 9. Неоптимальные шаги
Старайтесь как можно реже передавать промежуточные результаты на host для обработки с помощью CPU. Реализуйте если не весь алгоритм, то, по крайней мере, его основную часть на GPU, оставляя CPU лишь управляющие задачи. Автором этой статьи написана переносимая библиотека MGML_MATH для работы с простыми пространственными объектами, код которой работоспособен как на устройстве, так и на хосте.
Библиотека MGML_MATH может быть использована как каркас для написания CPU/GPU переносимых (или гибридных) систем расчета физических, графических или других пространственных задач. Основное ее достоинство в том, что один и тот же код может использоваться как на CPU, так и на GPU, и при этом во главу требований, предъявляемых к библиотеке, ставится скорость. Крис Касперски. Техника оптимизации программ. Эффективное использование памяти. - Спб.: БХВ-Петербург, 2003. - 464 с.: ил. CUDA Programming Guide 1.1 (http://developer.download.nvidia.com/compute/cuda/1_1/NVIDIA_CUDA_Programming_Guide_1.1.pdf
)
CUDA Programming Guide 1.1. page 14-15 CUDA Programming Guide 1.1. page 484.7. Выравнивание данных и выборка по 16 байт
4.8. Конфликты банков разделяемой памяти


4.9. Минимизация перемещений данных Host <=> Device
5. CPU/GPU переносимая математическая библиотека
6
.
Литература